
Broadcom has just introduced the Tomahawk Ultra networking chip, a direct competitor to Nvidia’s NVLink Switch. This chip is built to link hundreds of chips within a single rack, achieving a connection density four times greater than Nvidia’s offering. By adopting a high-speed, open-standards Ethernet protocol, Broadcom ensures seamless integration and adaptability across different infrastructures, avoiding proprietary limitations.

Manufactured by TSMC on a 5nm process, the Tomahawk Ultra is already shipping to major clients. Initially designed for high-performance computing, the chip pivoted toward AI applications due to soaring demand. This positioning allows Broadcom to capitalize on the increasing need for tightly connected, ultra-low latency compute clusters necessary for modern AI model training and inference, especially as models grow exponentially in complexity.
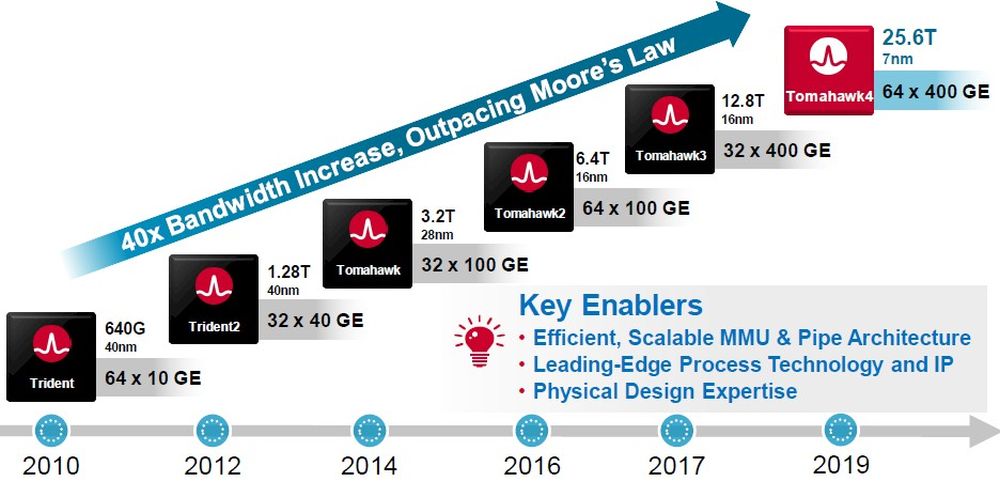
The real innovation lies in enabling a scale-up networking approach rather than scale-out, which enhances the capability to build vast, high-speed compute infrastructures. This positions Broadcom as a strong alternative for hyperscalers like Google, providing an option outside Nvidia’s proprietary ecosystem. The move underscores Broadcom’s expertise in high-speed networking, a critical domain for AI infrastructure.

Financially, Broadcom is reaping the rewards of AI demand, with its semiconductor division growing by 17% in the latest quarter and AI semiconductor revenues surging by 46% to reach $4.4 billion. The Tomahawk Ultra is a strategic asset, expanding Broadcom’s footprint in AI and providing a competitive edge in the rapidly evolving market of advanced compute networking solutions.

#Broadcom #AIChips #Networking #Semiconductors #Nvidia